The EPIC new IA-64
(It's not RISCY !)
�
Introduction
In June 1994 Intel and Hewlett
Packard announced their new partnership
in the microprocessor industry, an attempt by both companies to quash
their competitors. Hewlett Packard and Intel have put their heads together
and developed the IA-64, code named Merced, a 64-bit processor. With Merced
launch date set for the middle of 1999, articles regarding Merced are largely
based on what architects Jerry Huck (Hewlett Packard), and John Crawford
(Intel) revealed at the recent Microprocessor Forum. Intel and Hewlett Packard
have disclosed the key features of Merced, but have not provided a detailed
description of the new Instruction Set. Nonetheless what was revealed clearly
symbolises Merced as the way ahead, in comparison to today's RISC, PA-RISC,
and x86 chips
Merced's new instruction set has been designed to solve problems that
has plagued current architectures and is radically different from anything
ever attempted on mass market scale. Whether it succeeds or fails one thing
is for sure it will change the computer industry forever.
Merced is emphatically not a 64-bit extension of Intel's 32-bit x86 architecture,
nor an adaptation of Hewlett Packard's 64-bit PA-RISC architecture. Merced
includes several features that extract more parallelism - long
instruction words, branch elimination, and
speculative loading, to name a few.
On top of these features Intel and Hewlett Packard promise backward
compatibility with today's x86, and PA-RISC software, not a trivial
task. Introducing an architecture that is able to execute both IA-32(old)
and IA-64(new) software is ideal as it is difficult to convince customers
to switch from one day to the next. It allows the customer to move to the
new architecture slowly, for example, starting to rewrite critical parts
of the Operating System and convert larger applications later.
So what is the importance of the IA-64 compiler? This is the question
that will be answered in this article. The IA-64 the CPU must no longer
hurriedly analyze the instruction stream at run time to uncover hidden parallelism,
instead the compiler identifies the parallelism and binds this information
into the machine code for the CPU to use during the processing of the code.
(Back to top)
The Importance of the IA-64
Compiler
With the new IA-64 architecture, Intel's EPIC technique will shift complexity
to the compiler to create a simpler and faster microprocessor. The Merced
microprocessor uses several different techniques to extract as much parallelism
from program code as possible and to speed up processing. But all of these
techniques boil down to the use of the compiler. The new architecture uses
the compiler for forward planning by providing hinting instructions for
the CPU along with the instruction bundles in order to improve compiler/processor
cooperation. When a program is compiled, the compiler can determine a very
useful "model" of the data flow and logic of the program. Until
now, this information was unavailable to the CPU at run-time.
Intel's latest instruction set allows the compiler to advise the CPU
on what is likely to happen at run-time. A prime example of this is branch
predication. Branch predication, which will be discussed later, is used
to exploit as much parallelism as possible by eliminating branches at machine
level.
The IA-64 compiler is also responsible for speculative loading. The compiler
analyses the program, and looks for any operations which will need data
to be loaded from memory. It then places speculative load instructions and
speculative check instructions as early as possible in the code. These instruct
the CPU to load any required data, and verify the load, before the program
needs it at run-time. Again, this will be discussed in more detail later
on.
The new Merced architecture also explicitly groups instructions for parallel
execution. This involves Intel's EPIC instruction format which creates 128-bit
instruction bundles, each containing three instruction and an information
field tagged on to the end.
(Back to top)
The Instructions - The EPIC
Change
An important factor which contributes greatly towards the speed of an
architecture is the way in which it process it's instructions. The new instruction
set attempts, quite succesfully it seems, to resolve other problems with
current architectures. The new IA-64 uses a technique, normally referred
to as LIW(Long Instruction Words) encoding. This technique, which speeds
up instructions processing, involves packing the instructions into groups
or "bundles". However, Intel believe that the "LIW Encoding"
label has "negative connotations" so have chosen to name the technique
in their new architecture to be EPIC (Explicity Parallel Instruction Computing)
instead. They have used this EPIC/LIW technique to implement a new instruction
format which involves forming 128-bit instruction bundles, each containing
three fixed-length instructions ( about 40 bits long ) and a "template"
of several bits as shown below:-
 The template field of the bundle, which is placed there by the compiler,
provides grouping information and indicates to the CPU which instructions,
if any, in the bundle can be executed in parallel. the IA-64 instruction
format takes this parallelism even further allowing the template to also
indicate whether entire sequential instruction bundles can be executed in
parallel. This allows bundles to be chained together to create instruction
groups of any length. The template also indicates whether one or more instructions
must be executed serially, due to register dependencies. The purpose of
these templates in the bundles is to save CPU time, because without them,
as with previous architectures the CPU had to quickly scan the instruction
stream at run time to find any hidden parallelism. Now, any parallelism
is identified at the compiler stage, and so the compiler inserts this information
into the template fields of the bundles to save the CPUs time at run time.
The template field of the bundle, which is placed there by the compiler,
provides grouping information and indicates to the CPU which instructions,
if any, in the bundle can be executed in parallel. the IA-64 instruction
format takes this parallelism even further allowing the template to also
indicate whether entire sequential instruction bundles can be executed in
parallel. This allows bundles to be chained together to create instruction
groups of any length. The template also indicates whether one or more instructions
must be executed serially, due to register dependencies. The purpose of
these templates in the bundles is to save CPU time, because without them,
as with previous architectures the CPU had to quickly scan the instruction
stream at run time to find any hidden parallelism. Now, any parallelism
is identified at the compiler stage, and so the compiler inserts this information
into the template fields of the bundles to save the CPUs time at run time.
Each of the three instructions in the bundle contain the Opcode field,
one 6-bit Predicate Register (PR) field and three 7-bit General Purpose
Registers (GPR) fields as shown in the diagram above. These three GPRs are
the Source 1, Source 2, and Destination register fields of the instructions.
The PR field of each instruction is used to tell the CPU whether or not
to execute the instruction depending on the field's value being "true"
or "false".
These fields are specfic to integer and floating-point instructions and
so the IA-64 architecture have included 128 General Purpose Registers and
128 Floating Point Registers in the new architecture. This increased number
of registers can be taken advantage of by the compiler performing more "aggressive
optimizations". The new IA-64 processors will also include 64 one-bit
predicate registers.
Even though this EPIC technology isn't completely new and exciting with
it being largely based on the LIW technique, it does seem as though it was
a good move by Intel. For they have created a faster and more efficient
processor, but most of Intel's "forward-looking" architecture,
as this name suggests, just seems to be shifting work from the CPU at run-time
to the compiler. This will surely result in increased compiling time and
having to make the compiler more complex to allow it to find all of this
instruction parallelism.
(Back to top)
Predication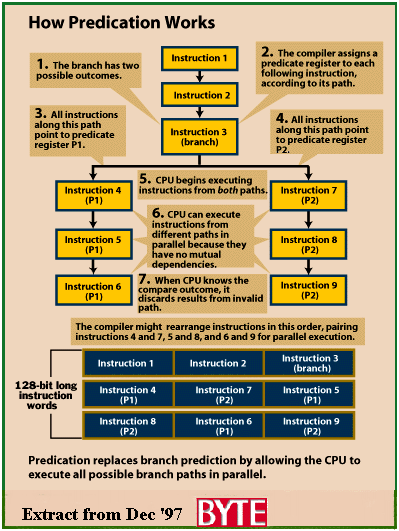
In previous architectures, when the CPU is presented with a branch, it
tries to predict the outcome of the branch and speculatively executes the
instructions.This can cause a heavy penalty in lost cycles if it is mispredicted.
IA-64's method of predication does not attempt to predict which way the
branch will fork, instead the IA-64 begins executing the code for every
possible branch outcome.
When the IA-64 encounters a branch statement in the source code it analyses
the branch to see if it is a suitable candidate for predication, as predication
can sometimes cost more cycles that it saves. If the compiler has determined
that predication will save more cycles than it will cost, it marks all the
instructions with a unique identifier called a predicate. For example, the
compiler might tag each instruction for a true and false branch, predicate
P1, and predicate P2, respectively. The IA-64 includes a predicate field
of 6-bits and so there are 64 unique predicates possible at any one time.
Any number of instructions that share a particular branch path will share
the same predicate. After tagging the instructions with the predicate field,
the compiler then determines which instructions the CPU can execute in parallel.
Please refer to diagram on the above.
At this point in the proceedings the IA-64 has most likely executed some
instructions from both possible paths (true and false) - but has not yet
stored any of the results. Before this final step is taken, the CPU checks
the predicate registers for each result. If the predicate register contains
a one, the instruction is valid, therefore the CPU retires the instruction
and stores the result. On the other hand if the predicate register contains
a zero, the CPU discards the result.
Predication effectively removes any negative impact of a branch instruction
at machine level. In effect, with the IA-64 system, there is no branch at
the machine level. There are several advantages to Predication, mostly at
machine level. Predication reduces code fragmentation as the compiler can
merge small basic blocks into larger blocks. The larger the block, the more
freedom the compiler has to rearrange instructions in order to extract more
parallism. It also reduces the penalty that current processors incur when
mispredicting branches. However, predication also has a down side - whatever
the outcome of the branch, the processor executes all of the possible branches,
and discards the results of the branch that is not required. As stated above,
the trick is to make sure that the CPU is saving more instructions than
it wastes.
(Back to top)
S peculative Loading
Speculative Loading is another technique used to extract more parallelism
from program code. It also helps in reducing the long latencies of memory
accesses. By 'hoisting' the load instruction higher in the instruction stream
it allows the processor to load data from memory long before it is needed.
This separation of the loading of data from the use of that data ensures
that the CPU, while waiting for data to load from memory, does not waste
time being idle.
Here is how speculative loading would handle a branch ( a decision statement,
such as an if-then-else) where one path contains a load instruction : -
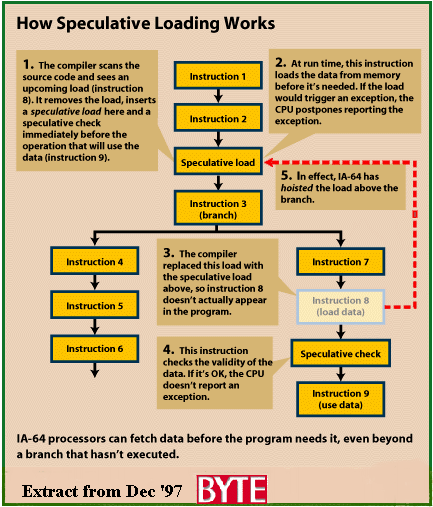 The compiler constantly analyses the source code looking for operations
that require the use of main memory, for example a load instruction. When
encountered, the compiler removes the load instruction and replaces it with
a speculative load instruction that is inserted into the instruction stream
before the operation that uses the data. If possible this can be above a
branch. A speculative load is used to load data from memory, several instructions
prior to its use.
The compiler constantly analyses the source code looking for operations
that require the use of main memory, for example a load instruction. When
encountered, the compiler removes the load instruction and replaces it with
a speculative load instruction that is inserted into the instruction stream
before the operation that uses the data. If possible this can be above a
branch. A speculative load is used to load data from memory, several instructions
prior to its use.
Simultaneously, the compiler rearranges the instructions to increase
parallelism, allowing the CPU to dispatch an unbroken stream of code that
executes more than one instruction at a time. This is achieved through "data
dependency", for example - an operation that requires the result of
a previous operation cannot execute in parallel with that operation.
When the CPU encounters a speculative load, it tries to retrieve the
data from memory. If the load is found to be invalid, the IA-64 will postpone
the reporting of an exception until the specualtive check is encountered.
By this time however, the branch that led to the exception has been resolved.
If the path taken by the branch includes the load, the speculative check
will report the load as invalid. Hence, the path is invalid and the CPU
reports an exception. However, if the path with the load is not taken, then
the speculative check is not executed and no exception is reported. This
method prevents an exception being reported even if the branch outcome doesn't
use the load instruction, as this would be a waste of clock cycles. Thus,
the specualtive check instruction acts as a safety-valve for exceptions.
Compare this to todays CPUs which speculatively execute instructions
beyond the branches. If the CPU guesses wrong, it must discard the speculative
results, flush the pipelines and reload the correct instructions - not to
mention causing exceptions when there may be no need to. This pays a heavy
penalty in lost cycles.
The IA-64's ability to load data from memory, long before it's needed
would be severely inhibited if a load could not be hoisted above a branch.
Since branches occur about every 6 instructions, the CPU would spend a lot
of time idle, waiting for data to be loaded from memory. Also, many exceptions,
(that need not be reported) have been eliminated. Another saving in clock
cycles. For these very reasons speculative loading is very powerful.
(Back to top)
Backward Compatibility
To make the transition from x86 (IA-32) to IA-64 smoother, Intel have
incorporated "backward compatibility" into the instruction set.
This means that Merced is able to execute x86 instructions (as well as the
new instruction set) and, hence, provides compatibility with a broad range
of x86 applications. To achieve this, the IA-64 actually contains 2 instruction
sets in one (Intel considers IA-64 to be a combination of the 2).
How has it been implemented?
Much speculation has arisen amongst experts as to how Intel would provide
support for IA-32 software. The main options are:
2. on-chip conversion via hardware (an expensive method)
The speculation ended when Intel's director of marketing for Merced,
Ron Curry, made the comment:
"We will provide support for the IA-32 software in hardware
- it will be hardware execution. It will execute those binaries directly.
It's not any sort of software translation."
This technique has been characterised as "dynamic translation",
basically meaning that the program is being translated as it is executed.
How will this be achieved?
Firstly, the Merced chip will be allowed to maintain a single system
interface that knows how to fetch instructions into the CPU by allowing
x86 and IA-64 code to intermix at all levels of memory hierarchy. The inefficiencies
of hardware translation have been eliminated as Merced will be able to accept
these new native-mode instructions directly from memory. The processor will
be optimised for native-mode execution rather than x86 execution.
To co-mingle code at the subroutine level, two decoders will be needed
and a mode bit may be used to direct code between them. Time-wise, changing
modes is on a par with a normal branch instruction. Most of a program can
exist in x86 code, however, subroutines and performance-critical inner loops
will have to be converted to IA-6 instructions.
Both types of register will also have to be implemented. x86 regis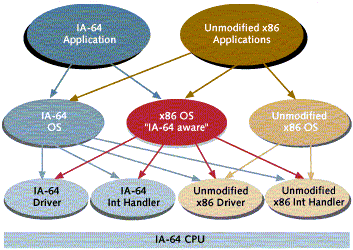 ters
will be accessed by x86 instructions whereas IA-64 registers will be accessed
by native instructions. It is expected that these registers will be implemented
in hardware as this will only require a small increase in the size of the
native register file.
ters
will be accessed by x86 instructions whereas IA-64 registers will be accessed
by native instructions. It is expected that these registers will be implemented
in hardware as this will only require a small increase in the size of the
native register file.
This design provides a great deal of flexibility in combining x86 and
IA-64 code. The allowable combinations of IA-64 and x86 applications, operating
systems, and low-level code are summarised in the diagram to the right.
�
(Back to top)
Conclusion
The new instruction set will deliver far more CPU performance than it
can with x86 processors. Although applications will have to be recompiled
to achieve optimal performance, an x86 application running on an IA-64 operating
system will see a significant increase in speed.
With backward compatibility and hardware and software support from Intel,
changing to the IA-64 instruction set is no more difficult than changing
from Pentium to Pentium II. Once cost and die-size reach suitable levels
for Merced, it is expected that IA-64 will dominate the workstation and
server markets, and rapidly displace x86 from the PC market.
Here will begin a diminishing support for RISC based systems.
(Back to top)
Disclaimer
We declare that each group member contributed equally in the production
of this IA-64 web-page report. This report is our own personal opinion based
on our interpretation of the information gathered from the sources listed
below.
Acknowledgements
�
 Angus
Macfarlane, William
Pitt, Donald MacDonald
BACK TO TOP
�
�
�
�
�
�
Angus
Macfarlane, William
Pitt, Donald MacDonald
BACK TO TOP
�
�
�
�
�
�